Làn sóng LLM đầu năm 2026: Kỷ nguyên tự vận hành và sự sụp đổ chi phí

Thị trường trí tuệ nhân tạo đang trải qua một giai đoạn biến động cực lớn mà các chuyên gia gọi là "Trận lở tuyết tháng Tư". Làn sóng LLM đầu năm 2026 không chỉ dừng lại ở việc tăng cường tham số, mà còn đánh dấu sự chuyển dịch sang tính hiệu quả kinh tế và khả năng tự chủ của các tác nhân (agents). Với sự tham gia của những gã khổng lồ như Alibaba, Xiaomi và các startup tiềm năng như MiniMax, bức tranh công nghệ đang thay đổi nhanh chóng hơn bao giờ hết.
- Chi phí suy luận: Giảm trung bình 50% so với thời điểm tháng 1/2026.
- Kiến trúc chủ đạo: Mixture-of-Experts (MoE) giúp tối ưu hóa tài nguyên tính toán.
- Đột phá: Các mô hình như MiniMax M2.7 đã có khả năng tự sửa lỗi và tiến hóa không cần sự can thiệp của con người.
- Tốc độ: Đạt ngưỡng 100 token/giây, cho phép triển khai các đội ngũ tác nhân (Agent Teams) phức tạp.
Sự trỗi dậy của kiến trúc Mixture-of-Experts (MoE) thế hệ mới
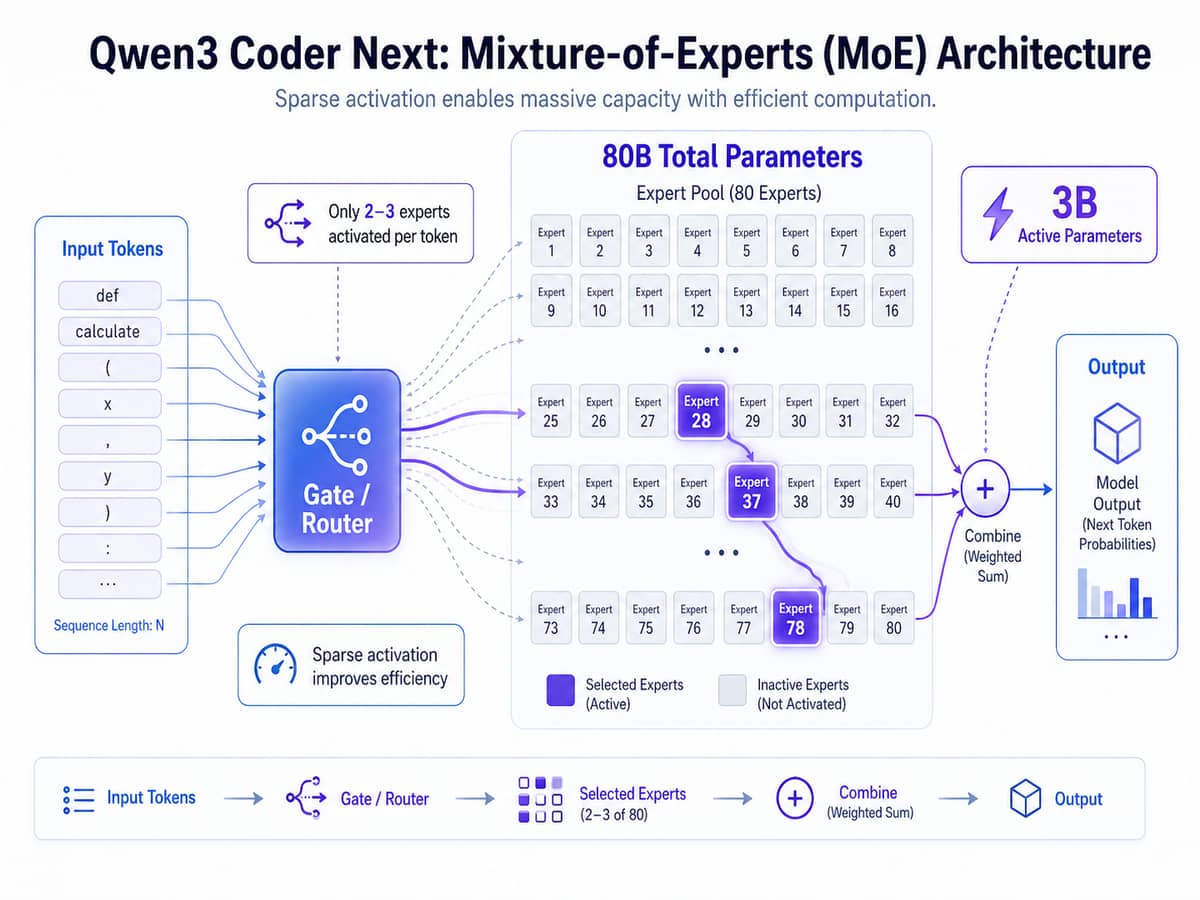
Trong giai đoạn đầu năm 2026, kiến trúc Mixture-of-Experts (MoE) đã trở thành tiêu chuẩn vàng cho các mô hình ngôn ngữ lớn (LLM) hiệu suất cao. Điển hình nhất là sự ra mắt của Qwen3 Coder Next từ đội ngũ Alibaba Qwen vào tuần đầu tiên của tháng 2 năm 2026. Đây là một minh chứng rõ nét cho việc tối ưu hóa tài nguyên mà không làm suy giảm trí thông minh của mô hình.
Qwen3 Coder Next sở hữu tổng cộng 80 tỷ tham số, nhưng nhờ cấu trúc MoE tinh vi, nó chỉ kích hoạt 3 tỷ tham số trong mỗi bước suy luận đơn lẻ. Việc kích hoạt thưa (sparse activation) này cho phép mô hình duy trì tốc độ xử lý cực nhanh trong khi vẫn đảm bảo độ sâu về tư duy logic. Đáng chú ý, Qwen3 Coder Next hỗ trợ cửa sổ ngữ cảnh (context window) lên đến 262.144 token, giúp các nhà phát triển có thể nạp toàn bộ mã nguồn của một dự án lớn vào bộ nhớ đệm để xử lý đồng nhất.
Dữ liệu từ cộng đồng DEV cho thấy Qwen3 Coder Next đã đạt được sự tương đồng về hiệu suất với Claude Sonnet 4.5 trong các tác vụ lập trình chuyên sâu. Điều này tạo ra một lợi thế cạnh tranh khổng lồ cho việc triển khai cục bộ trên các phần cứng cấp tiêu dùng (consumer-grade hardware). Thay vì phụ thuộc vào các API đám mây có độ trễ cao và chi phí đắt đỏ, các lập trình viên cá nhân hiện nay có thể sở hữu một trợ lý AI mạnh mẽ ngay trên máy trạm của mình.
MiniMax M2.7 và bước ngoặt của các mô hình tự tiến hóa
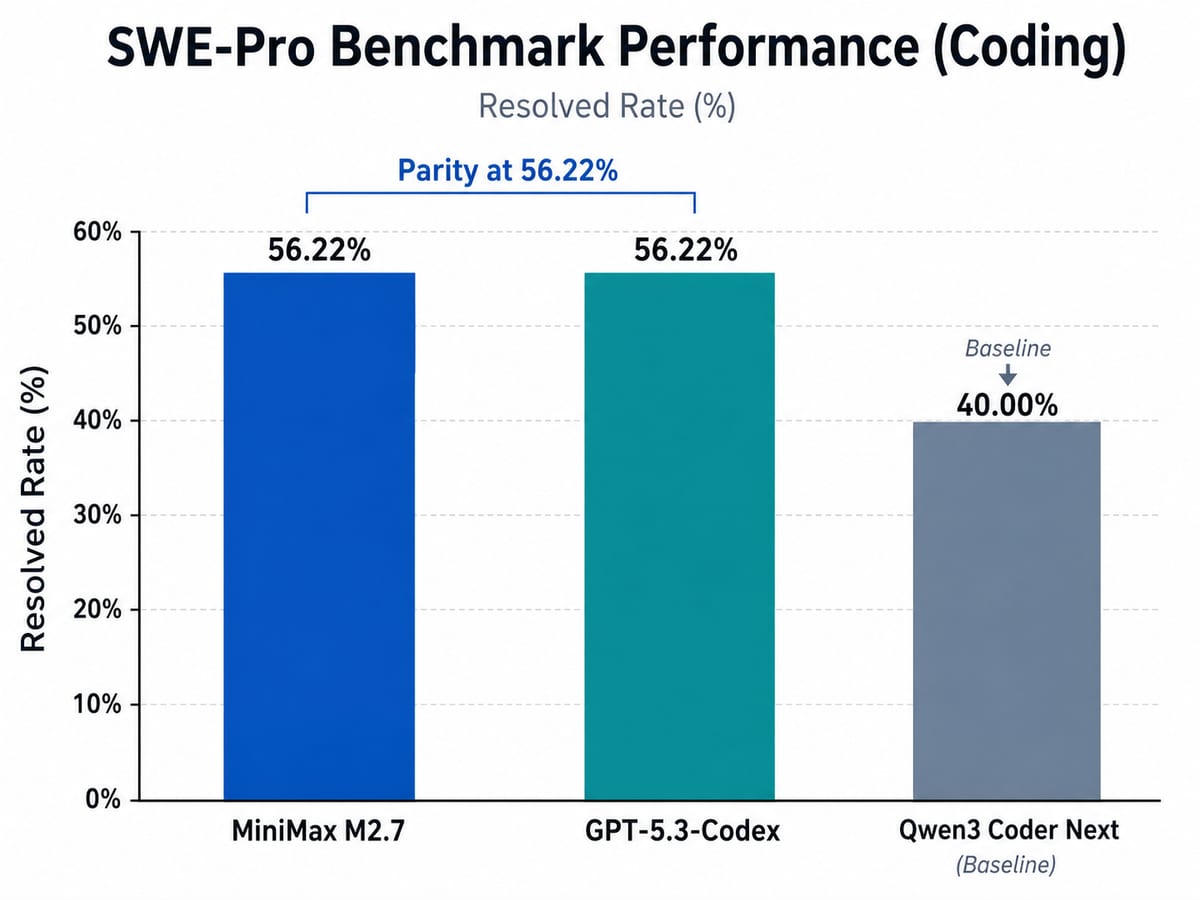
Nếu Alibaba tập trung vào hiệu suất phần cứng, thì startup MiniMax lại tạo nên một cú sốc trong làn sóng LLM đầu năm 2026 bằng khả năng tự tối ưu hóa của mô hình. Sau khi phát hành phiên bản M2.5 vào giữa tháng 2, MiniMax đã nhanh chóng tung ra siêu phẩm M2.7 vào ngày 18 tháng 3 năm 2026.
M2.7 sử dụng kiến trúc MoE lớn hơn với 230 tỷ tham số tổng cộng, kích hoạt 10 tỷ tham số cho mỗi lần suy luận. Trên thang đo SWE-Pro — một hệ thống đánh giá khả năng giải quyết các vấn đề kỹ thuật phần mềm thực tế — M2.7 đã ghi được điểm số ấn tượng 56,22%. Con số này chính thức đưa MiniMax ngang hàng với GPT-5.3-Codex của OpenAI, một cột mốc mà trước đây ít ai nghĩ một startup có thể đạt được trong thời gian ngắn như vậy.
Tuy nhiên, điểm đặc biệt nhất của M2.7 nằm ở phương thức nó được phát triển. MiniMax tiết lộ rằng đây là mô hình đầu tiên của họ tham gia sâu sắc vào quá trình tiến hóa của chính nó. Trong một môi trường thử nghiệm được cung cấp khung lập trình sẵn, M2.7 đã tự vận hành qua 100 vòng lặp. Nó tự phân tích các lỗi sai trong mã nguồn, sửa đổi logic và chạy các bài đánh giá để kiểm tra kết quả. Kết quả là mô hình đã tự cải thiện 30% hiệu suất mà không cần sự can thiệp trực tiếp của con người ở từng bước. Điều này mở ra một tương lai nơi các kỹ sư con người đóng vai trò là người giám sát (curators) thay vì là người viết từng dòng code.
Cuộc chiến giá cả: Chi phí suy luận giảm sâu
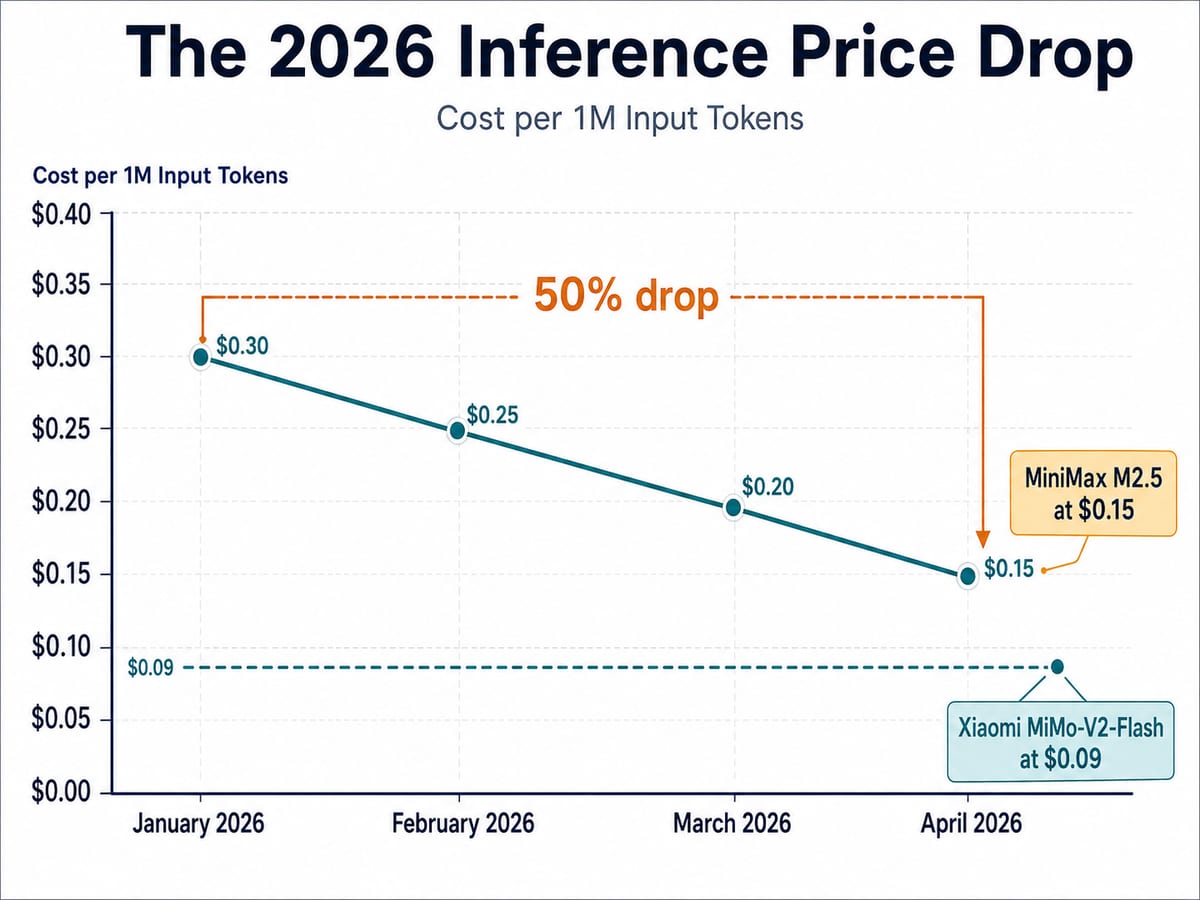
Sự cạnh tranh khốc liệt giữa các nhà cung cấp đã dẫn đến một cuộc đổ vỡ về giá trong làn sóng LLM đầu năm 2026. Xiaomi, một đối thủ đáng gờm từ lĩnh vực phần cứng, đã châm ngòi cho cuộc chiến này với mô hình MiMo-V2-Flash vào cuối năm 2025 và kéo dài ảnh hưởng sang năm 2026.
MiMo-V2-Flash ra mắt với mức giá gây gián đoạn thị trường: chỉ 0,09 USD cho mỗi triệu token đầu vào, đi kèm cửa sổ ngữ cảnh 256K. Ngay sau đó, MiniMax cũng định giá phiên bản M2.5 ở mức 0,15 USD/triệu token. Sự xuất hiện dồn dập của Claude 4.7 và GPT-5.5 trong tháng 4 năm 2026 đã đẩy áp lực giảm giá lên mức cao nhất. Dưới đây là bảng so sánh chi phí suy luận ước tính tại thời điểm tháng 4/2026:
| Mô hình Chi phí (USD/1M token đầu vào) Cửa sổ ngữ cảnh (Tokens) Đặc điểm nổi bật | |||
| Xiaomi MiMo-V2-Flash | 0.09 | 256,000 | Rẻ nhất thị trường |
| MiniMax M2.5 | 0.15 | 196,608 | Cân bằng hiệu suất |
| Qwen3 Coder Next | 0.12 (ước tính) | 262,144 | Tối ưu cho lập trình |
| Mô hình Tier-1 (GPT/Claude) | 0.40 - 0.60 | 500,000+ | Suy luận đa bước phức tạp |
Theo báo cáo từ TokenMix Research Lab, chi phí để vận hành một mô hình LLM "đủ tốt" cho các tác vụ doanh nghiệp đã giảm khoảng 50% chỉ trong vòng 3 tháng đầu năm 2026. Sự sụt giảm này đang dân chủ hóa quyền truy cập vào các quy trình làm việc dạng tác nhân (agentic workflows), cho phép các startup nhỏ có thể chạy các chuỗi suy luận phức tạp tiêu tốn hàng triệu token mà không lo ngại về ngân sách.
Tác động đến quy trình làm việc Agentic và doanh nghiệp
Với tốc độ đầu ra của MiniMax M2.7-Highspeed đạt 100 token mỗi giây — cải thiện 66% so với các phiên bản tiêu chuẩn — các doanh nghiệp đang dần từ bỏ hệ thống "nhắc - phản hồi" (prompt-response) đơn giản. Thay vào đó, họ đang xây dựng các "Đội ngũ tác nhân" (Agent Teams) có khả năng tìm kiếm công cụ động và suy luận dài hạn (long-horizon reasoning).
Trong bối cảnh làn sóng LLM đầu năm 2026, các tác nhân AI không còn chỉ trả lời câu hỏi. Chúng có thể tự động thực hiện các nhiệm vụ như:
- Tự động rà soát và sửa lỗi bảo mật trong toàn bộ kho lưu trữ mã nguồn của công ty.
- Quản lý chiến dịch marketing đa kênh bằng cách tự tạo nội dung, theo dõi chỉ số và điều chỉnh chiến lược theo thời gian thực.
- Phân tích dữ liệu tài chính phức tạp và đưa ra dự báo dựa trên hàng triệu trang tài liệu ngữ cảnh.
Sự chuyển dịch sang kiến trúc đa phương thức (multimodal) và tư duy "Hệ thống 2" (System 2 reasoning) cho phép AI giải quyết các vấn đề đòi hỏi sự tập trung và logic cao hơn. Tuy nhiên, tốc độ tiến hóa quá nhanh này cũng mang lại những rủi ro mới cho doanh nghiệp, đặc biệt là trong việc duy trì tính ổn định của hệ thống.
Thách thức về hiện tượng trôi dạt nhận thức (Perception Drift)
Một khái niệm mới đang trở thành nỗi lo ngại trong làn sóng LLM đầu năm 2026 chính là "hiện tượng trôi dạt nhận thức" (LLM perception drift). Khi các mô hình nền tảng được cập nhật hoặc tự tiến hóa liên tục, cách chúng hiểu và phản hồi cùng một câu lệnh có thể thay đổi theo thời gian. Điều này gây khó khăn cho các thương hiệu trong việc duy trì sự nhất quán trong các hệ thống tự động hóa.
Các doanh nghiệp hiện nay phải đầu tư thêm vào các lớp giám sát để đảm bảo rằng khi mô hình bên dưới tự tối ưu hóa, nó không vô tình làm thay đổi tông giọng thương hiệu hoặc vi phạm các quy tắc đạo đức đã thiết lập. Việc quản trị AI (AI Governance) từ một từ khóa xa lạ đã trở thành một ưu tiên then chốt trong chiến lược vận hành của các tập đoàn lớn vào năm 2026.
Câu hỏi thường gặp (FAQ)
Làn sóng LLM đầu năm 2026 có gì khác so với các năm trước?
Điểm khác biệt lớn nhất là sự chuyển dịch từ việc tăng quy mô tham số sang tối ưu hóa hiệu suất thông qua kiến trúc MoE và khả năng tự tiến hóa của mô hình. Chi phí suy luận giảm sâu 50% cũng là yếu tố then chốt giúp phổ cập AI agent vào thực tế doanh nghiệp thay vì chỉ dừng lại ở các thử nghiệm nhỏ lẻ.
Tại sao chi phí sử dụng LLM lại giảm mạnh vào đầu năm 2026?
Chi phí giảm nhờ hai yếu tố chính: kiến trúc Mixture-of-Experts (MoE) giúp giảm lượng tính toán cần thiết cho mỗi token và cuộc chiến giá cả khốc liệt giữa các nhà cung cấp như Xiaomi, Alibaba và MiniMax nhằm chiếm lĩnh thị phần người dùng lập trình và doanh nghiệp.
Mô hình tự tiến hóa như MiniMax M2.7 hoạt động thế nào?
Các mô hình này được đặt trong một môi trường giả lập với các công cụ lập trình và đánh giá. Chúng tự tạo ra mã nguồn, chạy thử, phân tích lỗi sai từ kết quả trả về và tự sửa đổi thuật toán của chính mình. Qua hàng trăm vòng lặp như vậy, mô hình đạt được hiệu suất tối ưu mà không cần kỹ sư con người can thiệp trực tiếp vào từng dòng lệnh.
Doanh nghiệp cần chuẩn bị gì trước làn sóng AI mới này?
Doanh nghiệp cần tập trung vào việc xây dựng hạ tầng dữ liệu sạch, thiết lập các khung quản trị AI để kiểm soát hiện tượng trôi dạt nhận thức và đào tạo nhân sự chuyển từ vai trò thực hiện sang vai trò giám sát và điều phối các đội ngũ tác nhân AI.
Kết luận
Làn sóng LLM đầu năm 2026 đã đánh dấu một cột mốc lịch sử khi rào cản về kinh tế và kỹ thuật đối với các tác nhân AI tự chủ chính thức sụp đổ. Với sự dẫn dắt của Qwen3 Coder Next và MiniMax M2.7, chúng ta đang bước vào một kỷ nguyên mà AI không chỉ là công cụ hỗ trợ, mà còn là những cộng sự có khả năng tự hoàn thiện. Để không bị bỏ lại phía sau, các nhà phát triển và doanh nghiệp cần nhanh chóng thích nghi với các quy trình làm việc dạng agentic và tận dụng lợi thế từ sự sụt giảm chi phí suy luận hiện nay.
Nếu bạn đang tìm kiếm các giải pháp tối ưu hóa quy trình làm việc với AI, hãy bắt đầu thử nghiệm các mô hình MoE ngay hôm nay để trải nghiệm sự khác biệt về hiệu suất và chi phí.